
Firebaseで作ったWebサービスを3ヶ月運用してみて、ハマったこと・知っておきたかったこと




Nuxt.jsとFirebaseで作っていたWebサービスを7月末にリリースして、はや3ヶ月。。
RDB脳なのでFirebaseを使った開発でいろいろとハマった。。そのポイントを整理してみました。
Firebaseをはじめようとしている人の一助になれば。
Nuxt.js(SPA)+Firebaseで作っています!
以前、以下のような記事を書いたのですが、そのFirebase関連ぽいまとめです。
・Nuxt.js(SPA)+Firebaseで積読用の読書管理サービスを作ってみたときにハマったこと... - Qiita
前回同様、内容的にはドキュメントをよく読めば書いてあることばかりですが、
実際に運用したり、機能追加したりする時に、気づくので、手戻りが多く...
あらかじめ、知っていたら良かったなと思う点をまとめています。
Firebaseはとてもよいですが、RDBに慣れ親しんでいると、
思わぬところでハマったり、運用してみて初めて分かることが多い感じに。。
ハマったことが多いですが、かなりコストを抑えて作れていてすごい( ゚д゚)!
というのが、Firebaseを使ってみた感想です♪
全体の構成はこんな感じ
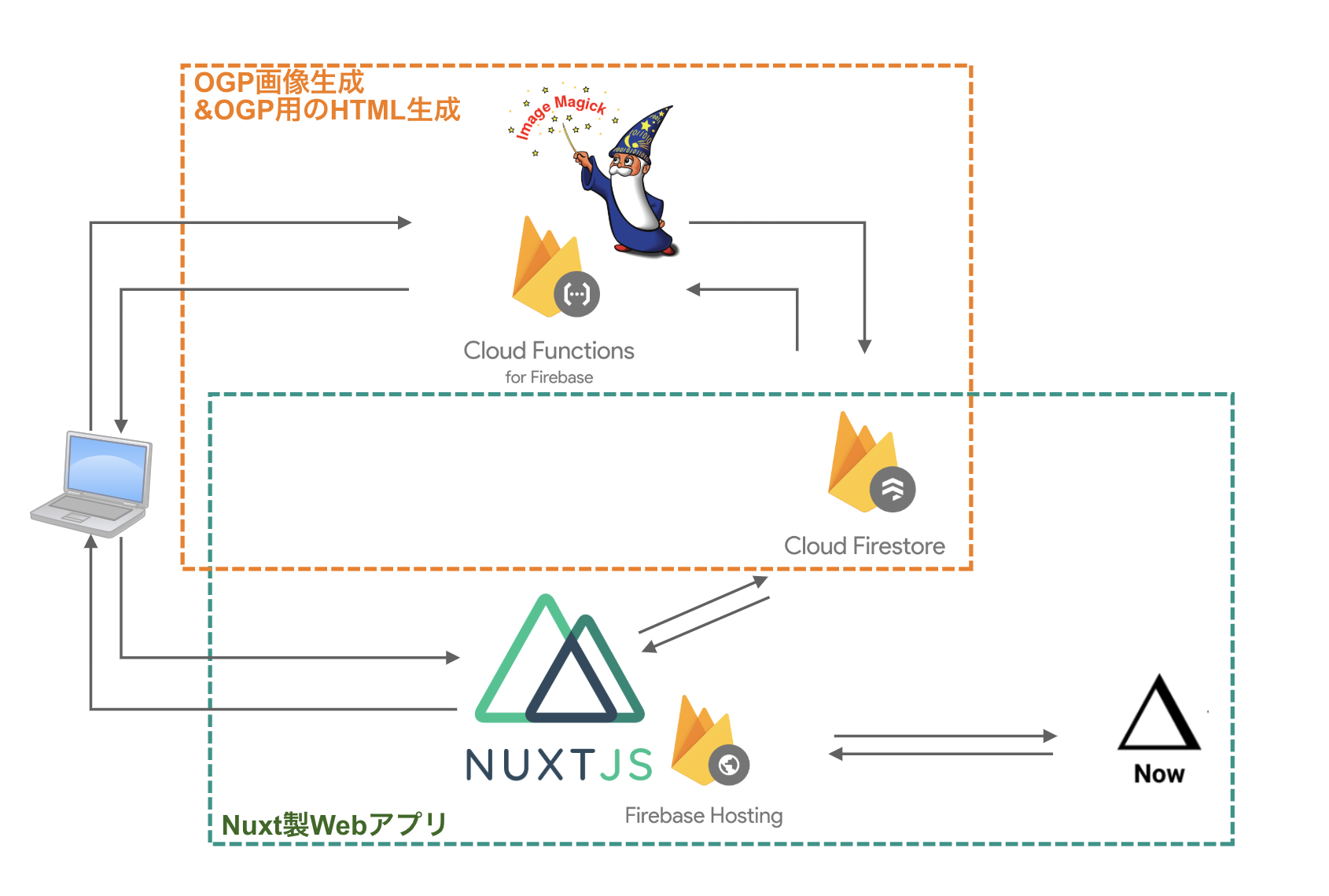
- SPAモードのNuxtアプリをFirebase Hositingにデプロイ
- データベースはFirestore
- OGP生成のためにCloud Function for Firebase+ImageMagic
- OGP用のHTML生成でCloud Function for Firebase
- 外部APIを利用したいのでZEIT NOW経由でのAPIを用意
わたしはここでハマりました。。
FirestoreでORがつかえない
DBを扱っているとORが使いたくなりますが、Firestoreでは使えません。。
公式ドキュメントのここに書いてある制約事項。。
論理 OR クエリ。この場合は、OR 条件ごとに独立したクエリを作成し、アプリでクエリ結果を結合する必要があります。

シンプルなクエリだったら複数回呼べばよいだけなので、あまり問題ないのですが、
orderByやlimitと一緒に使うと困ります。。
開発している積読ハウマッチだとこの部分。

- 読書中→積読の順序で表示して、
- 各ステータスは更新日時の降順で表示し、
- 30件ずつで表示する
という感じの処理をしています。
ORが使えないので、
- 読書中を検索
- 結果が30件未満だったら、残り分、積読を検索
という感じでやっています。
Firestoreで別フィールドでの範囲指定+orderByが使えない
これもFirestoreの制約事項。。
複数のフィールドに範囲フィルタを適用するクエリ(前のセクションの説明を参照)。
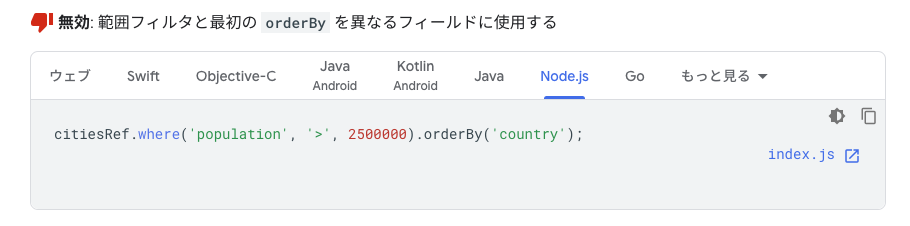
公式ドキュメントだとこのあたり。
複数のorderByとかは使えるけど、where+orderByだとダメ。
・Cloud Firestore で単純なクエリと複合クエリを実行する | Firebase
・Cloud Firestore でのデータの並べ替えと制限 | Firebase
たとえば、積読ハウマッチだと
- 持っている人が10人以上の本を、
- 更新日時の降順で並び替える
とかができない。。
実際にやる場合には、
- あらかじめ、持っている人が10人以上の本を別コレクションとして作成しておいて、
- そのコレクションに対して、更新日時の降順で並び替える
という形で対応する必要がある。。
開発当初・リリース前では、あまり気にならない制約事項だったけど、
リリース後の機能追加などで制約に引っかかるように。。
ドキュメントフィールドの削除はFieldValue.delete()
公式ドキュメントにちゃんと書いてあるけど、
ドキュメントフィールドを削除したいときは、FieldValue.delete()を使わないといけない。。
雰囲気で使い始めたときは、nullをセットすると削除できると思ってて、
そのままnullがセットされてた(´ω`)
更新するときは、updateとset({merge: true})がある
公式ドキュメントをよく読むと書いてあるけど、更新する方法は2種類ある。
updateは、ドキュメント全体を置き換えるset({merge: true})は、一部のドキュメントフィールドを置き換える
set({merge: true})については、すこし解釈が違うけどこんなイメージ。
公式ドキュメントの説明では、こんな感じ。
ドキュメントが存在するかどうかわからない場合は、新しいデータを既存のドキュメントに結合するオプションを渡し、ドキュメント全体が上書きされないようにします。
たとえば、こんなドキュメントがあって、
{
name: "Alice",
age: 20
}
年齢を30歳に変えたいなと思った場合、こんな感じ。
const docRef = db.collection("user").doc("Alice");
// updateの場合、すべてのドキュメントフィールドを渡さないといけない
await docRef.update({ name: "Alice", age: 30 })
// set({merge: true})の場合、変更したいドキュメントフィールドだけ渡せばOK
await docRef.set({ age: 30 }, { merge: true })
間違えて、updateで変更したいドキュメントフィールドだけにすると。。
const docRef = db.collection("user").doc("Alice");
// updateの場合、すべてのドキュメントフィールドを渡さないといけない
await docRef.update({ age: 30 })
// =>
// {
// age: 30
// }
こんな感じで、name: "Alice"が消えてしまいます。。
その名の通り、マージなので、新しいドキュメントフィールドを追加したいときにも便利(´ω`)
const docRef = db.collection("user").doc("Alice");
await docRef.set({ bookNum: 0 }, { merge: true })
// =>
// {
// name: "Alice",
// age: 30,
// bookNum: 0
// }
マイグレーションするときは、これを使って、フィールドを追加したりしている(´ω`)
トランザクション内では最大500件まで
公式ドキュメントだとこのあたり。
・トランザクションと一括書き込み | Firebase
制約がいくつか書かれているけど、以下のな感じ。
- トランザクション内では、書き込みよりも読み込みを先にしないといけない
- トランザクションが最大リクエストサイズの10MiBまで
- 1度でできる書き込みは最大500のドキュメントまで
特に気になるのが、書き込みは最大500のドキュメントの部分。
何千件も更新しないといけない場合に、問題が発生してきます。。
5000件あると、10個のトランザクションに分ける必要がありますが、
たとえば、1000件目で失敗した場合、最初の500件のみ実行される状態でエラーに。。
そうなった場合、どこでエラーが起きたかを記録する仕組みがないと大変なことに。。
積読ハウマッチでは、ログなど既存の情報から復元することで対応可能でしたが、
エラーが発生した場合、そのログを残しておくなどの仕組みがあるとよいなと。。
バグがないように作るのは大事なのですが、バグが起こったときに、
リカバリできる情報や手段を用意しておくのも同じく大事。。
Firestoreトリガーは不整合を起こしやすい
Firestoreで変更があったら、Cloud Functionsを呼ぶCloud Firestoreトリガー。
特定パスのCRUDに応じて、処理を組み込めるので便利。
・Cloud Firestore トリガー | Firebase
ただ、トランザクションと同じ感じで、トランザクションが分断されるので要注意。。
クライアント側でトランザクションを使っていたとしても、
トリガーで起動するCloud Firestoreはトランザクションに含まれません。。
そのため、クライアント側で正常終了したと思っても、
Cloud Firestore側でエラーが起こると、全体として不整合が起こった状態になります。。
Firestoreトリガーを使うときは、
トランザクションを分けてもよい処理なのかをよく検討する必要があります。。
Firestoreのスキーマ変更が大変
Firestoreはドキュメント型のNoSQLで、NoSQLはクエリ志向のDBです。
そのため、クエリが増える・変わるとスキーマを変更する必要が出てきます。
たとえば、「〇〇の総数」みたいなのはドキュメントフィールドとして値を持たせる必要があり、
あとでほしいと思った時に、マイグレーションが必要になってきます。。
Firestoreには分散カウンタという便利なものがありますが、
次のコードは、分散カウンタを初期化します。
と記載されているとおり、値が0のドキュメントフィールドが必要だったり。。
なので、ローカルPCでfirebase-adminを実行して、
Firestoreのデータを変更する仕組みを用意しておく必要があります。
ローカルPCでfirebase-adminを実行するときの話はこちらの記事に。
・ローカルPCからfirebase-adminを使ってFirestoreを操作する(管理ツール)
・ローカルPCでfirebase-adminを使って一括削除/一括更新する - Qiita
ただ、ドキュメント数が1万とかだと、
あっという間に無料枠を使い切るので、頻繁な変更は要注意。。
(とはいえ、1日に2万件の読み込みが無料だったり、)
(10万件ごとに$0.18/20円くらいなので100万件でも200円くらい。)
(RDBで100万レコードを扱うよりも、安い気がしてきている)
おわりに
わりとネガティブな内容になっている気もしますが、
制約を制約として認識していれば、問題ない話ばかりだと思ってます。
大変だったのは手探りでやっていたため、後で知ることになったため。。
設計とかする前に知っておきたかったまとめです。。
個人的にはFirebaseはとてもよく、
かなりコストを抑えてサービスを公開できてすごい( ゚д゚)!
というのが、Firebaseを使ってみた感想です♪
気をつけることも多いですが、慣れれば大丈夫(´ω`)
とはいえ、プロダクトによっては合わないこともあるので、なにかの参考になれば!
こんなのつくってます!!
積読用の読書管理アプリ 『積読ハウマッチ』をリリースしました!
積読ハウマッチは、Nuxt.js+Firebaseで開発してます!

もしよかったら、遊んでみてくださいヽ(=´▽`=)ノ
機能追加が増えると知見も貯まるので、貯まったらまた記事を書こうと思います♪
要望・感想・アドバイスなどあれば、
公式アカウント(@MemoryLoverz)や開発者(@kira_puka)まで♪

フリーエンジニア/今はNuxt.js/いつかFlutter 受託&アプリ/Webサービス/ゲームを #個人開発 CS修士→SIer/R&D→フリー #paiza はAランクで満足/AtCoderしたい #DMでお仕事募集はお休み中 Kotlin/Python/Swift/Unity/Java/Haskell/DDD
Crieitは誰でも投稿できるサービスです。 是非記事の投稿をお願いします。どんな軽い内容でも投稿できます。
また、「こんな記事が読みたいけど見つからない!」という方は是非記事投稿リクエストボードへ!
こじんまりと作業ログやメモ、進捗を書き残しておきたい方はボード機能をご利用ください。
ボードとは?

コメント